Usando datos extraídos de Spotify, analizamos variables como la bailabilidad, energía, valentía y su relación con el éxito durante el año 2023, así como echamos también un vistazo al comportamiento pormenorizado de las canciones de un único cantante, Feid.
Autores/as
Manuel Gimeno (magilli@alumni.uv.es)
Cristina Tormos (tordela@alumni.uv.es)
Fecha de publicación
20 de diciembre de 2023
Introducción
El siguiente trabajo está dividido en dos partes. En primer lugar, llevamos a cabo un análisis exhaustivo de las tendencias en la música popular de 2023 con datos extraídos directamente de Spotify. El enfoque particular de este estudio surge de variables que caracterizan las canciones más populares, como la “bailabilidad”, “energía” y “valentía”. Además, se trata de establecer una relación entre dichas variables y la popularidad de las canciones en diferentes plataformas, como la propia Spotify, Apple Music y Deezer. Utilizando una combinación de técnicas estadísticas y visualizaciones avanzadas, buscamos descubrir patrones y relaciones clave entre estas características musicales y métricas de éxito.
En la segunda parte, nos centramos en el artista Feid y el trabajo adquiere un enfoque concreto que no solo se dirige hacia la popularidad y distribución de las canciones de Feid en las plataformas de streaming musical, sino que también nos permite explorar las características musicales de sus canciones y su relación con otros artistas.
El objetivo del trabajo es ver a nivel global y a nivel particular qué comportamiento experimentan las canciones, qué coincidencias se encuentran a nivel de popularidad y qué tendencias se aprecian.
Los datos se pueden cargar en la memoria de R/RStudio con este código:
Código
#Cargamos librerías necesariaslibrary(ggplot2)library(plotly)library(corrplot)library(dplyr)library(reshape2)library(tidyverse)library(tidyr)library(cluster)library(gt)library(gtExtras)library(gridExtra)library(fmsb)library(radarchart)library(gganimate)library(ggwordcloud)library(png)library(ggrepel)library(patchwork)library("vembedr")#Cargamos los datos desde el archivo CSVfile_path <-"datos/spotify-2023.csv"df <-read.csv(file_path, stringsAsFactors =FALSE)#Preparamos los datos: Limpieza y conversión de tipos de datosdf$streams <-as.numeric(gsub("[^0-9]", "", df$streams))df$in_deezer_playlists <-as.numeric(gsub("[^0-9]", "", df$in_deezer_playlists))df$in_shazam_charts <-as.numeric(gsub("[^0-9]", "", df$in_shazam_charts))df$track_name_clean <-iconv(df$track_name, to ="ASCII", sub ="")df$artist.s._name <-iconv(df$artist.s._name, to ="UTF-8")
Primera parte: Comportamiento, coincidencias y tendencias de las canciones más populares de 2023.
Análisis global de canciones y número de reproducciones.
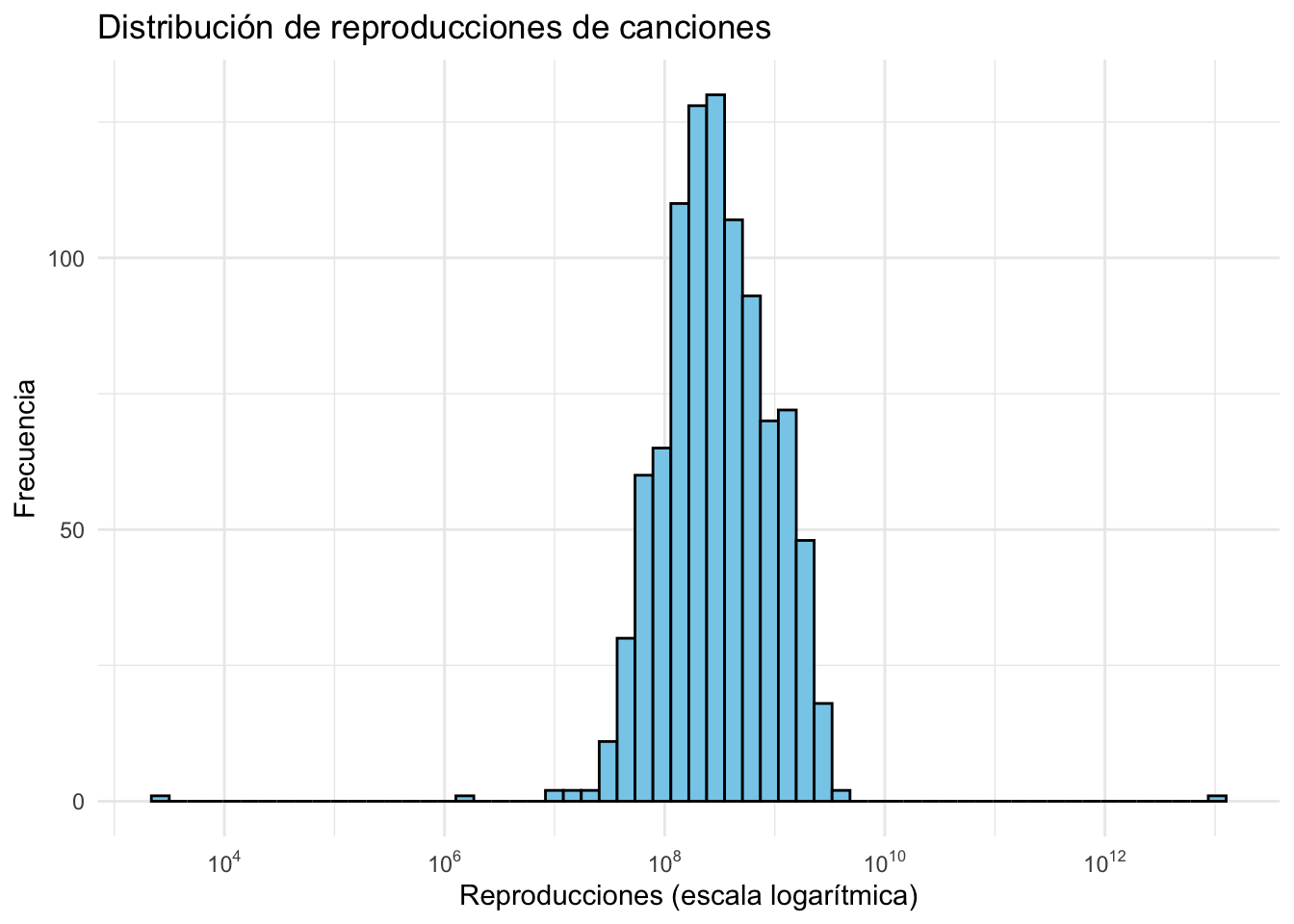
#Creamos el histograma:ggplot(df, aes(x = streams)) +geom_histogram(bins =60, fill ="skyblue", color ="black") +scale_x_log10(breaks = scales::trans_breaks("log10", function(x) 10^x),labels = scales::trans_format("log10", scales::math_format(10^.x))) +theme_minimal() +labs(title ="Distribución de reproducciones de canciones",x ="Reproducciones (escala logarítmica)",y ="Frecuencia")
Iniciamos el proyecto con un análisis detallado de la distribución de reproducciones entre las canciones, empleando un histograma transformado logarítmicamente. Este enfoque no solo aclara la distribución de las reproducciones entre un gran número de canciones populares, sino que también resalta las tendencias generales y los patrones de popularidad. Este análisis es crucial para entender la dinámica del éxito en plataformas de streaming musical y para identificar qué nivel de reproducciones es común entre las canciones más populares.
Objetivo: Analizar cómo se distribuyen las reproducciones entre las canciones populares.
Método: Utilización de un histograma transformado logarítmicamente para una representación clara y detallada de la distribución de las reproducciones.
Este histograma nos permite agrupar las canciones al dividir las reproducciones hasta en 60 veces. De esta manera, es posible apreciar con qué frecuencia aparecen canciones en el TOP 1000 que tengan un número determinado de reproducciones. A pesar de ser un base de datos caracterizada por la popularidad, dentro de esta exposición existen diferencias de reproducciones, como puede observarse con la forma de campana de Gauss que ofrece le histograma.
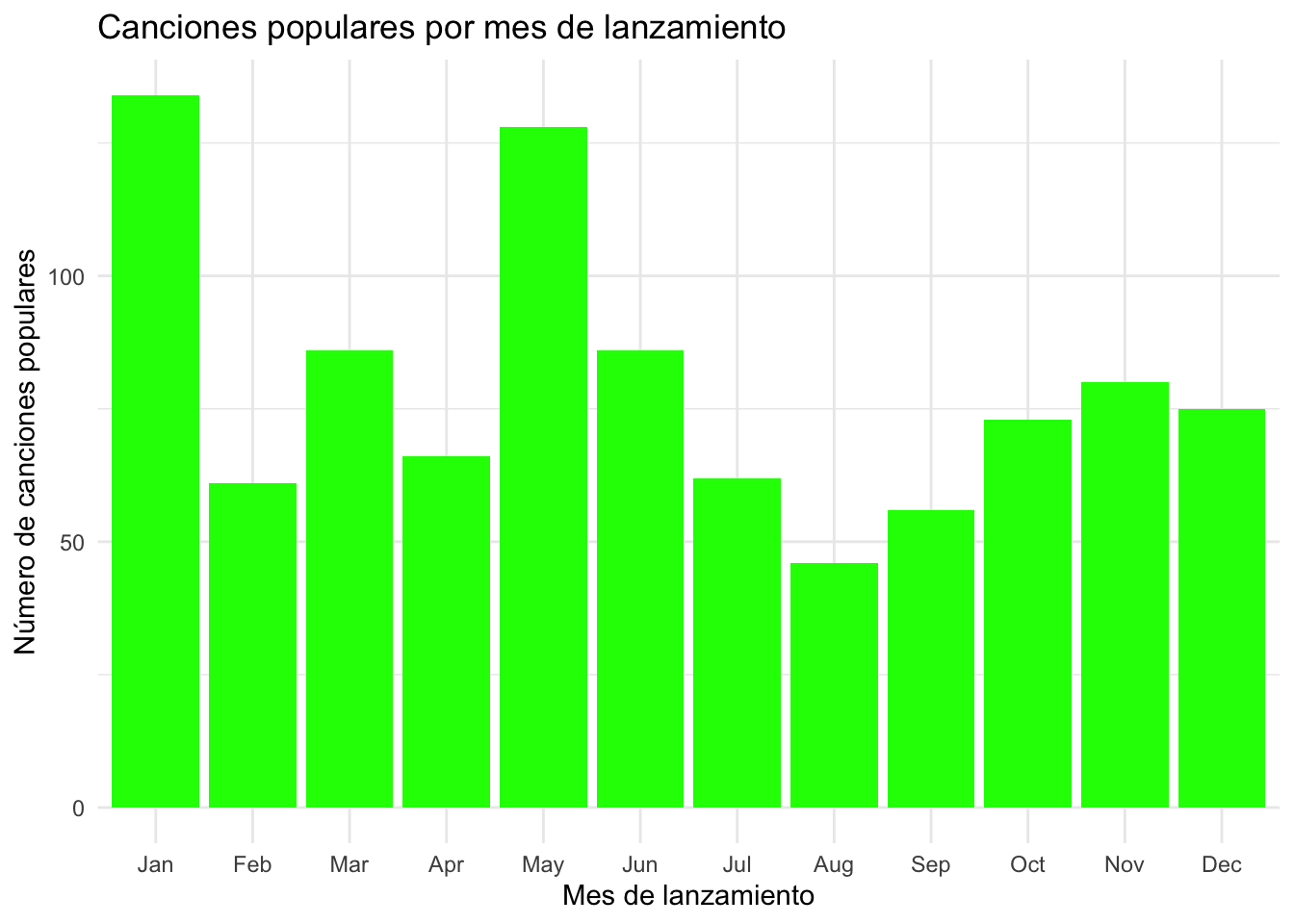
# Convertimos "released_month" a factor con etiquetas de mes para poder trabajarlo en el gráfico de barrasdf$released_month <-factor(df$released_month, levels =1:12, labels = month.abb)# Creamos el gráfico de barras para las canciones más populares por mes de lanzamientoggplot(df, aes(x = released_month)) +geom_bar(fill ="green") +theme_minimal() +labs(title ="Canciones populares por mes de lanzamiento",x ="Mes de lanzamiento",y ="Número de canciones populares")
Investigamos también factores como el mes de lanzamiento de las canciones y su influencia en la popularidad. Mediante gráficos de barras analizamos qué meses en particular recogen la mayor cantidad de éxitos, pudiendo entrever estrategias de marketing y tendencias de consumo.
Objetivo: Investigar si el mes de lanzamiento influye en la popularidad de las canciones.
Método: Creación de un gráfico de barras para mostrar la cantidad de canciones populares lanzadas cada mes.
Con este gráfico de barras observamos que los meses de lanzamiento que aglutinan las canciones más populares son los meses de enero y mayo. Esta agrupación destacada evidencia una concentración de canciones alrededor de dos meses que, con toda seguridad, han sido seleccionados de manera previa por las discográficas para generar un impacto superior debido a eventos y tendencias concretas que se desarrollan en el sector musical.
Número de reproducciones por cantidad de artistas participantes
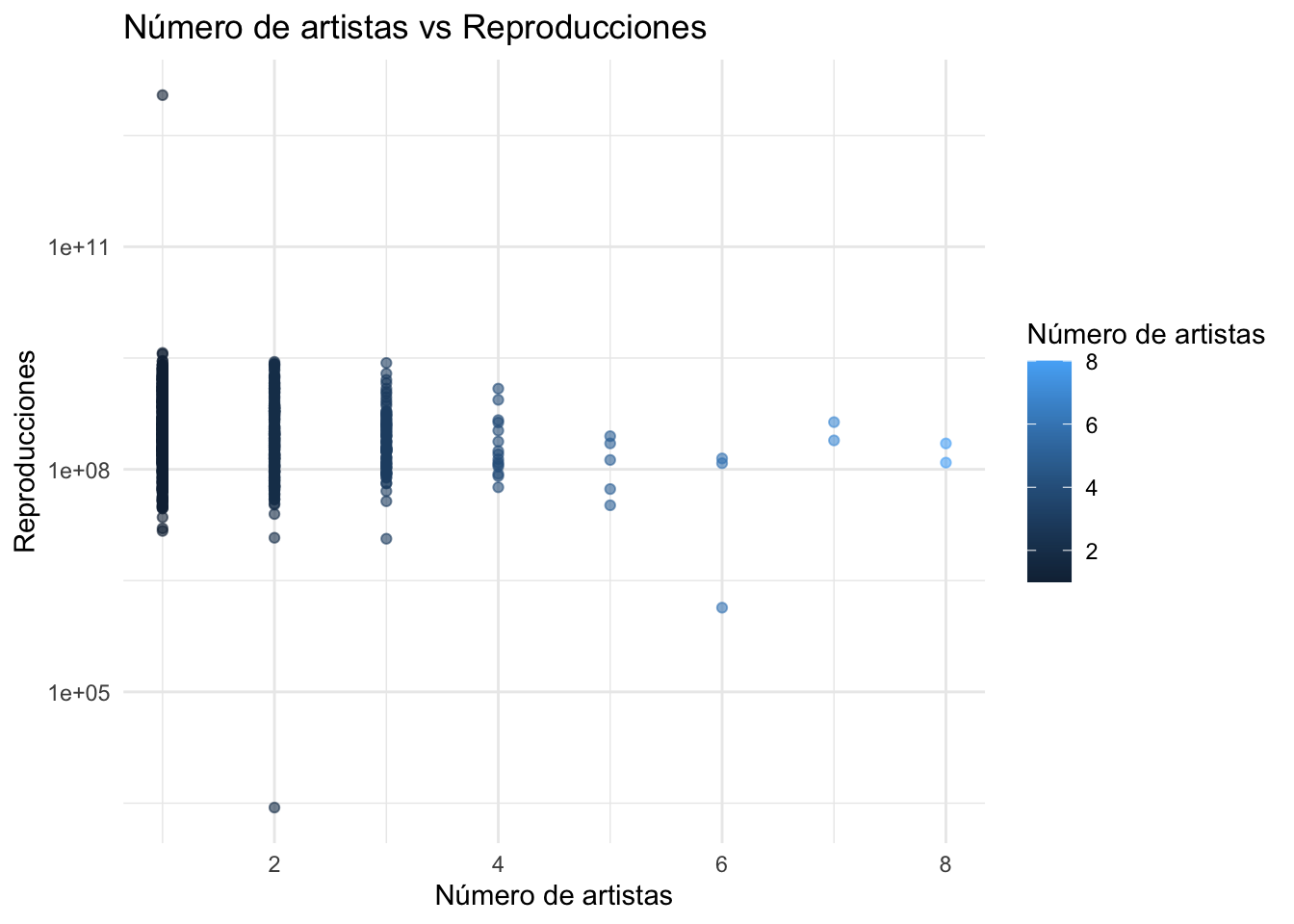
#Creamos el gráfico de dispersiónggplot(df, aes(x = artist_count, y =as.numeric(streams))) +geom_point(aes(color = artist_count), alpha =0.6) +scale_y_log10() +theme_minimal() +scale_color_continuous(name ="Número de artistas") +labs(title ="Número de artistas vs Reproducciones",x ="Número de artistas",y ="Reproducciones")
Del mismo modo, tratamos de encontrar alguna relación o tendencia entre las canciones con mayores reproducciones con la cantidad de artistas que participan en cada una de ellas.
Objetivo: Explorar la relación entre el número de artistas en una canción y su éxito en términos de reproducciones.
Método: Uso de un gráfico de dispersión para visualizar esta relación, con una transformación logarítmica en el eje de las reproducciones.
Este gráfico de dispersión deja muy a las claras que los mayores éxitos en cuanto a cantidad de ellos mismos se produce con un solo artista como protagonista, siendo este un resultado esperado. Sin embargo, al mismo tiempo, también vemos que los temas musicales lanzados por una sola persona son los que mayor cantidad de reproducciones ofrecen. No existe un dato extremo o “outlier” que supere a los temas populares protagonizados por un artista en solitario.
Relación entre características musicales y rango de popularidad por cuartiles
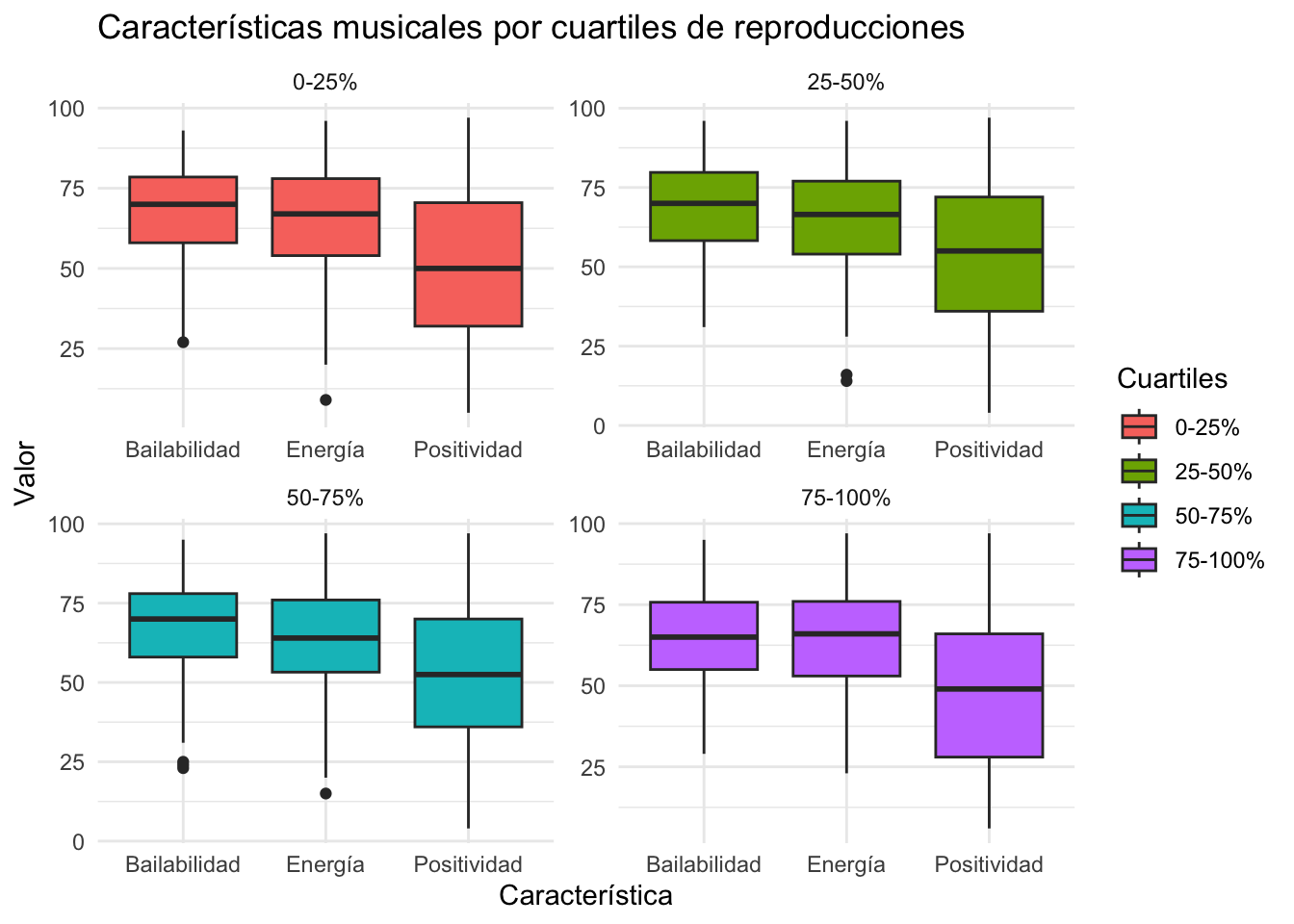
# Definimos los cuartiles de reproduccionescuartile_breaks <-quantile(df$streams, probs =seq(0, 1, by =0.25))# Creamos una nueva columna en el dataframe para indicar el grupo de cuartildf$stream_cuartile_group <-cut(df$streams, breaks = cuartile_breaks, include.lowest =TRUE, labels =c("0-25%", "25-50%", "50-75%", "75-100%"))#Transformamos el dataframe para visualizacióndf_melted <-melt(df, id.vars ="stream_cuartile_group", measure.vars =c("danceability_.", "energy_.", "valence_."))# Creamos el gráfico de cajaggplot(df_melted, aes(x = variable, y = value, fill = stream_cuartile_group)) +geom_boxplot() +scale_x_discrete(labels =c("Bailabilidad", "Energía", "Positividad")) +theme_minimal() +labs(title ="Características musicales por cuartiles de reproducciones",x ="Característica",fill ="Cuartiles",y ="Valor") +facet_wrap(~stream_cuartile_group, scales ="free")
Una parte significativa del estudio la dedicamos a explorar de qué forma características específicas de las canciones como la “bailabilidad”, la “energía” y la “positividad” se correlacionan con su éxito en términos de reproducciones. Al dividir las canciones en cuartiles según su número de reproducciones, es posible destacar utilizando gráficos de caja y comparar las distribuciones de estas características musicales dentro de cada cuartil. Este análisis detallado proporciona información sobre qué atributos musicales son más importantes en las canciones de mayor éxito.
Objetivo: Examinar la relación entre la popularidad de las canciones (medida en reproducciones) y sus características musicales (“bailabilidad”, “energía”, “positividad”).
Método: Clasificación de las canciones en cuartiles según sus reproducciones y posterior análisis de las características musicales para cada cuartil mediante gráficos de caja.
Los resultados de estos gráficos de cajas son sorprendentes. Curiosamente, el cuartil donde se aglutinan las canciones más popualres (es decir, el grupo de 75%-100%) es el que dispone el rango de “positividad” más bajo, tanto en su máximo como en su mínimo. Los valores de “bailabilidad” y “energía” también son sensiblemente inferiores. Esta situación puede deberse a las tendencias musicales actuales.
Análisis de la correlación entre características musicales y presencia en listas de reproducción
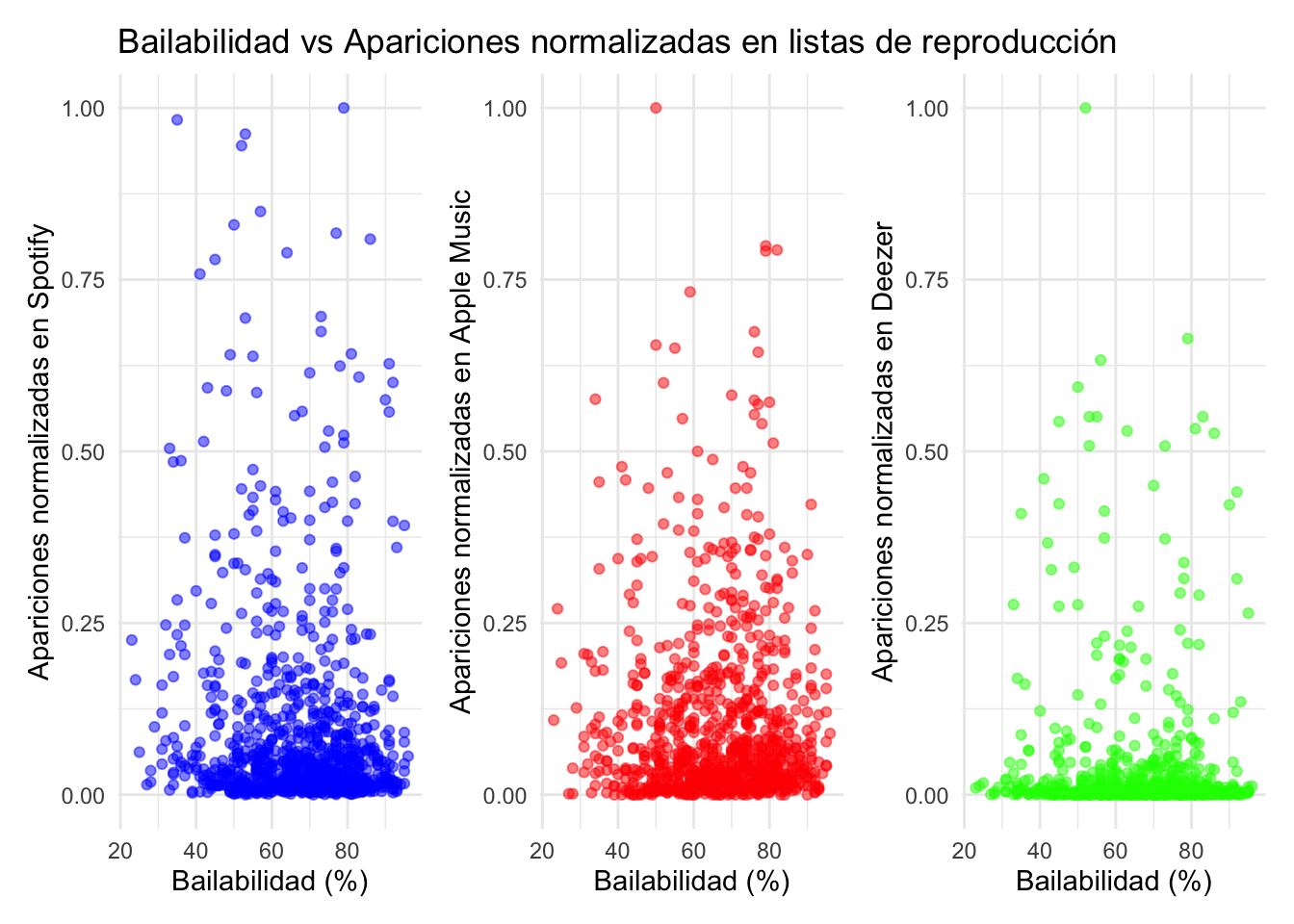
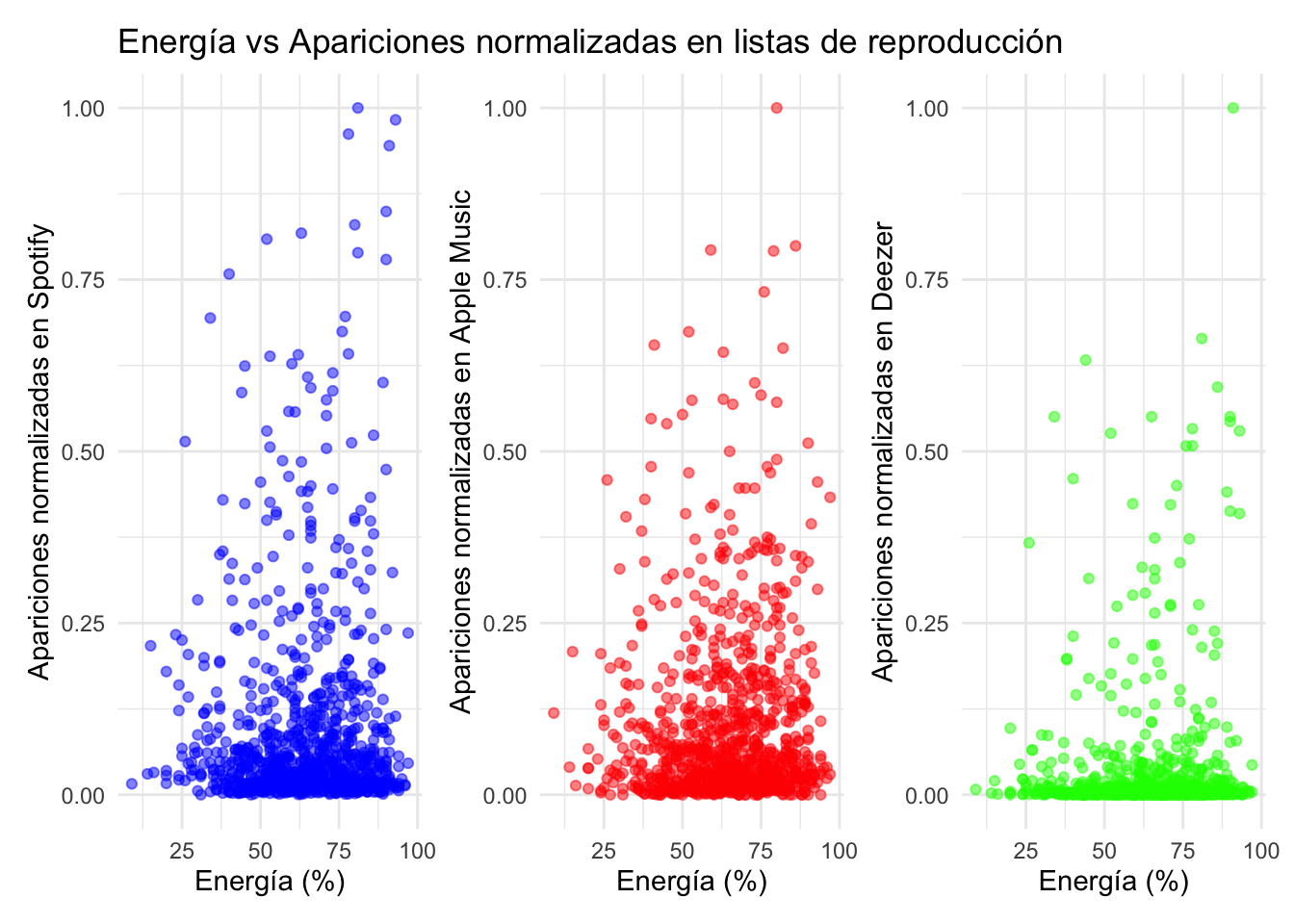
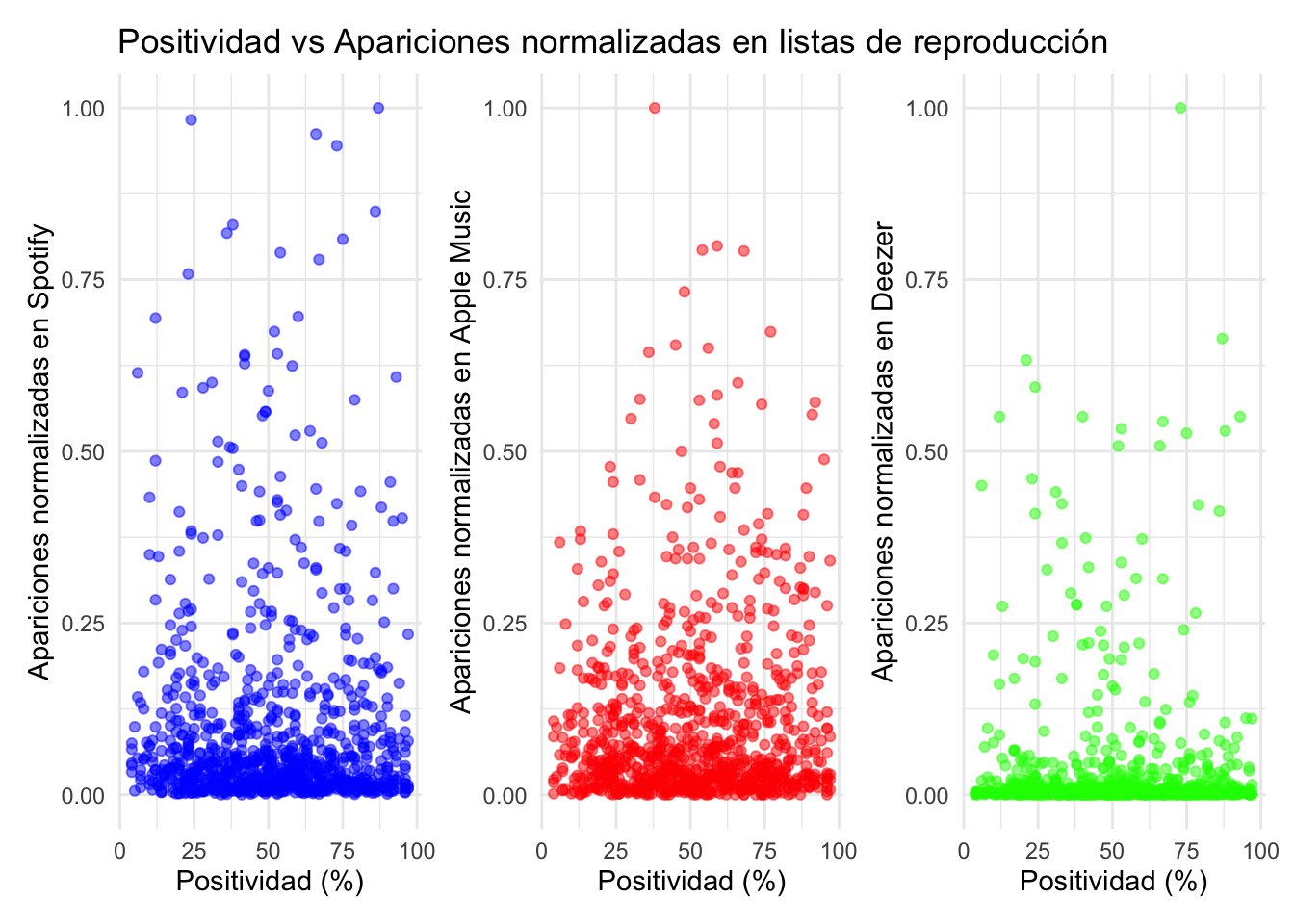
# Creamos los gráficos para mostrar las diferencias...# Función para normalizar los datosnormalize <-function(x) { (x -min(x, na.rm =TRUE)) / (max(x, na.rm =TRUE) -min(x, na.rm =TRUE))}# Normalizamos las columnas de apariciones en listas de reproduccióndf <- df %>%mutate(in_spotify_playlists_norm =normalize(in_spotify_playlists),in_apple_playlists_norm =normalize(in_apple_playlists),in_deezer_playlists_norm =normalize(in_deezer_playlists))# Eliminamos filas con valores NA en las columnas relevantesdf_clean <- df %>%filter(!is.na(danceability_.) &!is.na(in_spotify_playlists_norm) &!is.na(in_apple_playlists_norm) &!is.na(in_deezer_playlists_norm))# Bailabilidad# Gráfico Spotifyp1 <-ggplot(df_clean, aes(x = danceability_., y = in_spotify_playlists_norm)) +geom_point(alpha =0.5, color ="blue") +labs(title ="Bailabilidad vs Apariciones normalizadas en listas de reproducción",x ="Bailabilidad (%)",y ="Apariciones normalizadas en Spotify") +theme_minimal()# Gráfico Apple Musicp2 <-ggplot(df_clean, aes(x = danceability_., y = in_apple_playlists_norm)) +geom_point(alpha =0.5, color ="red") +labs(x ="Bailabilidad (%)",y ="Apariciones normalizadas en Apple Music") +theme_minimal()# Gráfico Deezerp3 <-ggplot(df_clean, aes(x = danceability_., y = in_deezer_playlists_norm)) +geom_point(alpha =0.5, color ="green") +labs(x ="Bailabilidad (%)",y ="Apariciones normalizadas en Deezer") +theme_minimal()# Combinamos los gráficoscombined_plot <- p1 + p2 + p3 +plot_layout(guides ='collect')# Mostramos el gráfico combinadocombined_plot# Energía# Gráfico Spotifyp1 <-ggplot(df_clean, aes(x = energy_., y = in_spotify_playlists_norm)) +geom_point(alpha =0.5, color ="blue") +labs(title ="Energía vs Apariciones normalizadas en listas de reproducción",x ="Energía (%)",y ="Apariciones normalizadas en Spotify") +theme_minimal()# Gráfico Apple Musicp2 <-ggplot(df_clean, aes(x = energy_., y = in_apple_playlists_norm)) +geom_point(alpha =0.5, color ="red") +labs(x ="Energía (%)",y ="Apariciones normalizadas en Apple Music") +theme_minimal()# Gráfico Deezerp3 <-ggplot(df_clean, aes(x = energy_., y = in_deezer_playlists_norm)) +geom_point(alpha =0.5, color ="green") +labs(x ="Energía (%)",y ="Apariciones normalizadas en Deezer") +theme_minimal()# Combinamos los gráficoscombined_plot1 <- p1 + p2 + p3 +plot_layout(guides ='collect')# Mostramos el gráfico combinadocombined_plot1# Positividad# Gráfico Spotifyp1 <-ggplot(df_clean, aes(x = valence_., y = in_spotify_playlists_norm)) +geom_point(alpha =0.5, color ="blue") +labs(title ="Positividad vs Apariciones normalizadas en listas de reproducción",x ="Positividad (%)",y ="Apariciones normalizadas en Spotify") +theme_minimal()# Gráfico Apple Musicp2 <-ggplot(df_clean, aes(x = valence_., y = in_apple_playlists_norm)) +geom_point(alpha =0.5, color ="red") +labs(x ="Positividad (%)",y ="Apariciones normalizadas en Apple Music") +theme_minimal()# Gráfico Deezerp3 <-ggplot(df_clean, aes(x = valence_., y = in_deezer_playlists_norm)) +geom_point(alpha =0.5, color ="green") +labs(x ="Positividad (%)",y ="Apariciones normalizadas en Deezer") +theme_minimal()# Combinamos los gráficoscombined_plot2 <- p1 + p2 + p3 +plot_layout(guides ='collect')# Mostramos el gráfico combinadocombined_plot2
En este caso buscamos averiguar si las características musicales específicas —bailabilidad, energía y positividad— de las canciones se correlacionan con su presencia en listas de reproducción en distintas plataformas de streaming musical (Spotify, Apple Music y Deezer).
Objetivo: El análisis busca identificar si ciertas características musicales están más asociadas con una mayor inclusión en listas de reproducción en cada plataforma.
Método: Normalización de los datos para una correcta comparación y gráficas de dispersión para una mejor visualización.
Estos gráficos de dispersión no han arrojado una gran diferenciación entre el perfil de los usuarios que añaden canciones a sus playlist particulares. La mayor diferencia a simple vista es la de Deezer, pero esta situación puede deberse a que el funcionamiento de la plataforma no fomenta tanto la creación de playlist en comparación con Spotify y Apple Music.
# Análizamos los clusters utilizando k-meansset.seed(123) # Esto sirve para la reproductibilidadkmeans_result <-kmeans(df[, c("danceability_.", "energy_.", "valence_.")], centers =4)# Añadimos la asignación de clusters al dataframedf$cluster <-as.factor(kmeans_result$cluster)# Creamos una nueva columna para nombres de cluster personalizadosdf$cluster_name <-paste("Cluster", df$cluster)#Gráfico de canciones por clustersplot_ly(df, x =~danceability_., y =~energy_., z =~valence_., color =~cluster_name, text =~track_name_clean, colors =c('red', 'blue', 'green', 'yellow'),marker =list(size =10), type ='scatter3d', mode ='markers') %>%layout(title ="Análisis de clusters de canciones",scene =list(xaxis =list(title ='Bailabilidad'),yaxis =list(title ='Energía'),zaxis =list(title ='Positividad')))
Por último, uno de los aspectos más importantes del trabajo ha sido poder agrupar las canciones más populares por clusters. Estos clusters tienen en cuenta las tres características cualitativas de las canciones para Spotify, como son la “bailabilidad”, la “energía” y la “positividad”. Esta clasificación sirve para encontrar canciones con elementos comunes y así poder concretar con mayor precisión qué elementos son necesarios para que un tema musical pueda llegar a ser extremadamente popular.
Objetivo: Agrupar canciones con características similares y analizar estos grupos.
Método: Uso del algoritmo k-means para clasificar las canciones en clusters según características musicales, así como visualización mediante un gráfico 3D.
Más que sacar conclusiones, este gráfico, usando el algoritmo kmeans, nos permite agrupar canciones por las variables “bailabilidad”, “energía” y “positivdad” y trazar así una relación entre todas ellas. Esta información por clusters puede ser muy útil como investigación de qué elementos debe tener una canción para ser de éxito y, al mismo tiempo, cómo debe ser en términos musicales si se quiere encuadrar dentro de un grupo determinado. Con herramientas de inteligencia artificial, esta información podría ser útil para crear canciones usando como modelos los temas de cada cluster.
Segunda parte: Ferxxo en el foco. Aproximación a un cantante de éxito
Preparamos los datos para la siguiente fase del trabajo:
Código
#Filtramos el df para Feid.df_feid <- df %>%filter(grepl("Feid", artist.s._name, ignore.case =TRUE))
Biografia del artista
Salomón Villada Hoyos (Medellín, 19 de agosto de 1992), mejor conocido por su nombre artístico Feid o por su alter ego Ferxxo, es un cantante, compositor y productor discográfico colombiano.
Con una energía positiva, muy buen rollo y colaboraciones junto a varios artistas, Feid nos trae la banda sonora urbana del 2023.
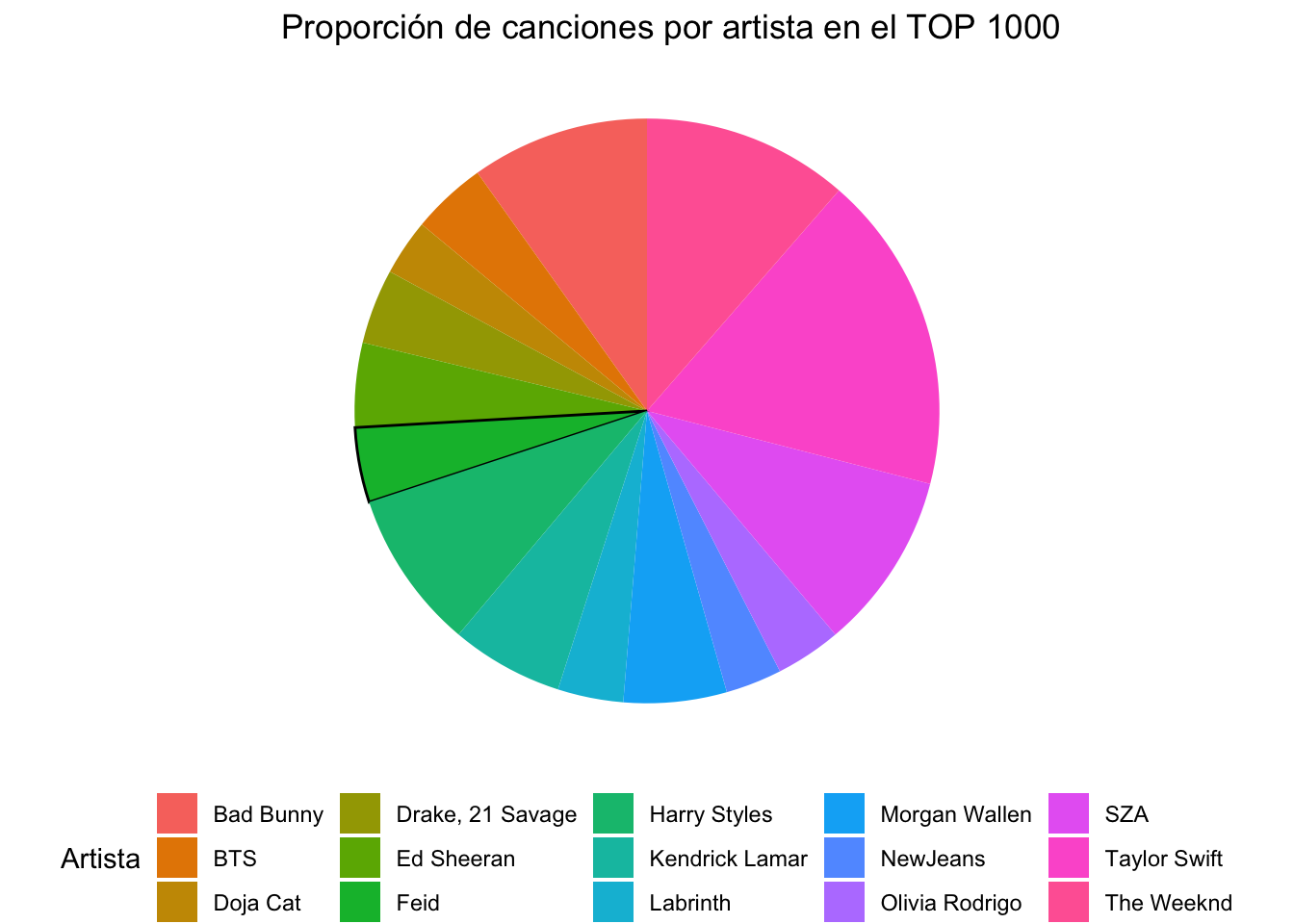
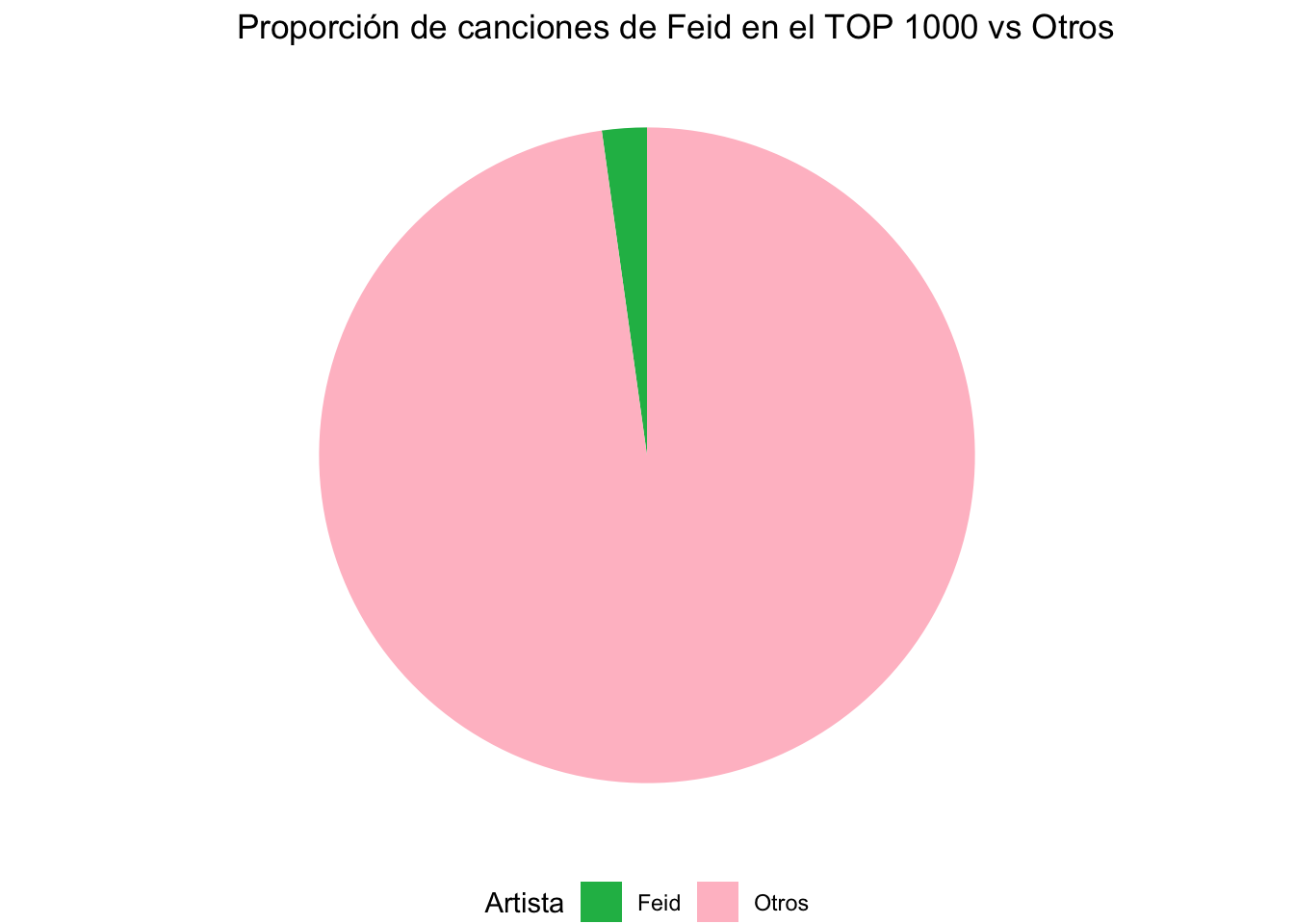
#Primero comparamos todos los cantantes# Contamos la cantidad de canciones por artistacount_df_artist <-table(df$artist.s._name)# Filtramos los artistas con más de cinco cancionesfiltered_count_df_artist <- count_df_artist[count_df_artist >5]# Creamos un dataframe para los gráficosdf_circ_artist <-data.frame(artist =names(filtered_count_df_artist), count =as.numeric(filtered_count_df_artist))# Creamos el gráfico circular para todos los artistas:c1 <-ggplot(df_circ_artist, aes(x ="", y = count, fill = artist)) +geom_bar(stat ="identity", width =1, color =ifelse(df_circ_artist$artist =="Feid", "black", NA)) +coord_polar("y", start =0) +labs(title ="Proporción de canciones por artista en el TOP 1000", fill ="Artista",x =NULL, y =NULL) +theme_void() +theme(legend.position ="bottom")c1# Creamos otro gráfico para comparar al Ferxxo con los otrosc2 <-ggplot(df, aes(x ="", fill =ifelse(grepl("Feid", artist.s._name, ignore.case =TRUE), "Feid", "Otros"))) +geom_bar(stat ="count", width =1) +coord_polar("y", start =0) +labs(title ="Proporción de canciones de Feid en el TOP 1000 vs Otros",fill ="Artista",x =NULL, y =NULL) +theme_void() +theme(legend.position ="bottom") +scale_fill_manual(values =c("Feid"="#1DB954", "Otros"="pink")) c2
Adentrándonos en el análisis de la distribución de canciones por artista, destacamos la proporción de canciones de Ferxxo en comparación con otros artistas entre las canciones más populares de 2023. Utilizamos un gráfico circular para ilustrar de forma clara y sencilla la diversidad artística.
Objetivo: Examinar cómo se distribuyen las canciones entre Feid y otros artistas.
Método: Uso de gráficos circulares para visualizar la proporción de canciones de Feid en comparación con otros artistas.
Con los gráficos circulares, podemos observar la significativa presencia de Ferxxo en el panorama musical de 2023. Esto nos sugiere que se encuentra entre las preferencias de los oyentes.
Éxitos en el TOP 10: Las 10 canciones más escuchadas de Ferxxo en 2023
# Top 10:# Filtramos el df para Feid y ordenamos según la variable streamsdf_feid <- df %>%filter(grepl("Feid", artist.s._name, ignore.case =TRUE)) %>%arrange(desc(streams))# Sacamos las 10 canciones más escuchadastop_10_feid <- df_feid[1:10, ]# Renombramos las columnastop_10_feid <- top_10_feid %>%rename("Cancion"= track_name,"Artista"= artist.s._name,"Reproducciones"= streams,"Bailabilidad"= danceability_.,"Positividad"= valence_.,"Energia"= energy_.,"Acustica"= acousticness_.,"Viveza"= liveness_. )#Cambiamos el nombre de una canción para omitir algunos caracteres:top_10_feid <- top_10_feid %>%mutate(Cancion =ifelse(Cancion =="Feliz Cumplea��os Fe", "Feliz Cumpleaños Ferxxo", Cancion))# Seleccionamos las variables de interéstabla_top_10_feid <- top_10_feid %>%select(Cancion, Artista, Reproducciones, Bailabilidad, Positividad, Energia, Acustica, Viveza) %>%gt(rowname_col ="Cancion") %>%tab_header(title =md("**TOP 10 FEID**"),subtitle =md("*Canciones más escuchadas*") ) %>%cols_align(align ="center") %>%cols_align(align ="right", columns =c("Cancion", "Artista")) %>%cols_merge(columns =c("Cancion", "Artista"), pattern ="{1} - {2}") %>%cols_label(Cancion ="Cancion",Artista ="Artista",Reproducciones =paste0("🔄", " Reproducciones"),Bailabilidad =paste0("💃", " Bailabilidad"),Positividad =paste0("😃️", "Positividad"),Energia =paste0("⚡️", " Energia"),Acustica =paste0("🎸", " Acustica"),Viveza =paste0("🔊", " Viveza"), ) %>%opt_row_striping() %>%opt_table_font(font =google_font("Amatic SC")) %>%tab_options(column_labels.background.color ="#39423c",footnotes.background.color ="#39423c",source_notes.background.color ="#39423c",heading.background.color ="#39423c",heading.align ="left" ) %>%tab_style(style =cell_text(color ="#1DB954", size =px(32)), locations =cells_title("title"))#Mostramos la tabla:tabla_top_10_feid
TOP 10 FEID
Canciones más escuchadas
🔄 Reproducciones
💃 Bailabilidad
😃️Positividad
⚡️ Energia
🎸 Acustica
🔊 Viveza
Hey Mor - Ozuna, Feid
674072710
90
40
59
0
10
Feliz Cumpleaños Ferxxo - Feid
601863821
87
57
55
10
29
Yandel 150 - Yandel, Feid
585695368
78
58
73
5
10
LA INOCENTE - Feid, Mora
477033549
76
46
79
31
7
Normal - Feid
459276435
71
59
56
4
27
CHORRITO PA LAS ANIMAS - Feid
345031710
74
61
83
11
35
Classy 101 - Feid, Young Miko
335222234
86
67
66
14
12
ULTRA SOLO REMIX - De La Ghetto, Feid, Polima WestCoast, Paloma Mami, Pailita
279717388
91
59
82
8
6
Ferxxo 100 - Feid
278920007
70
58
57
25
15
Pantysito - Feid, Alejo, Robi
273005485
83
63
74
14
16
A continuación, es posible descubrir los éxitos más destacados de Ferxxo mientras se filtran y se ordenan sus canciones según la cantidad de reproducciones. Esta tabla muestra las canciones más populares, abordando aspectos como reproducciones, bailabilidad, positividad, energía, acústica y viveza.
Objetivo: Identificar las canciones más populares de Feid.
Método: Ordenar las canciones de Feid por número de reproducciones y seleccionar las 10 principales.
Con esta tabla, hemos querido reflejar las 10 canciones mejor acogidas por los oyentes, además de mostrar las características individuales de cada canción.
Explorando en profundidad las características del TOP 10 de Ferxxo
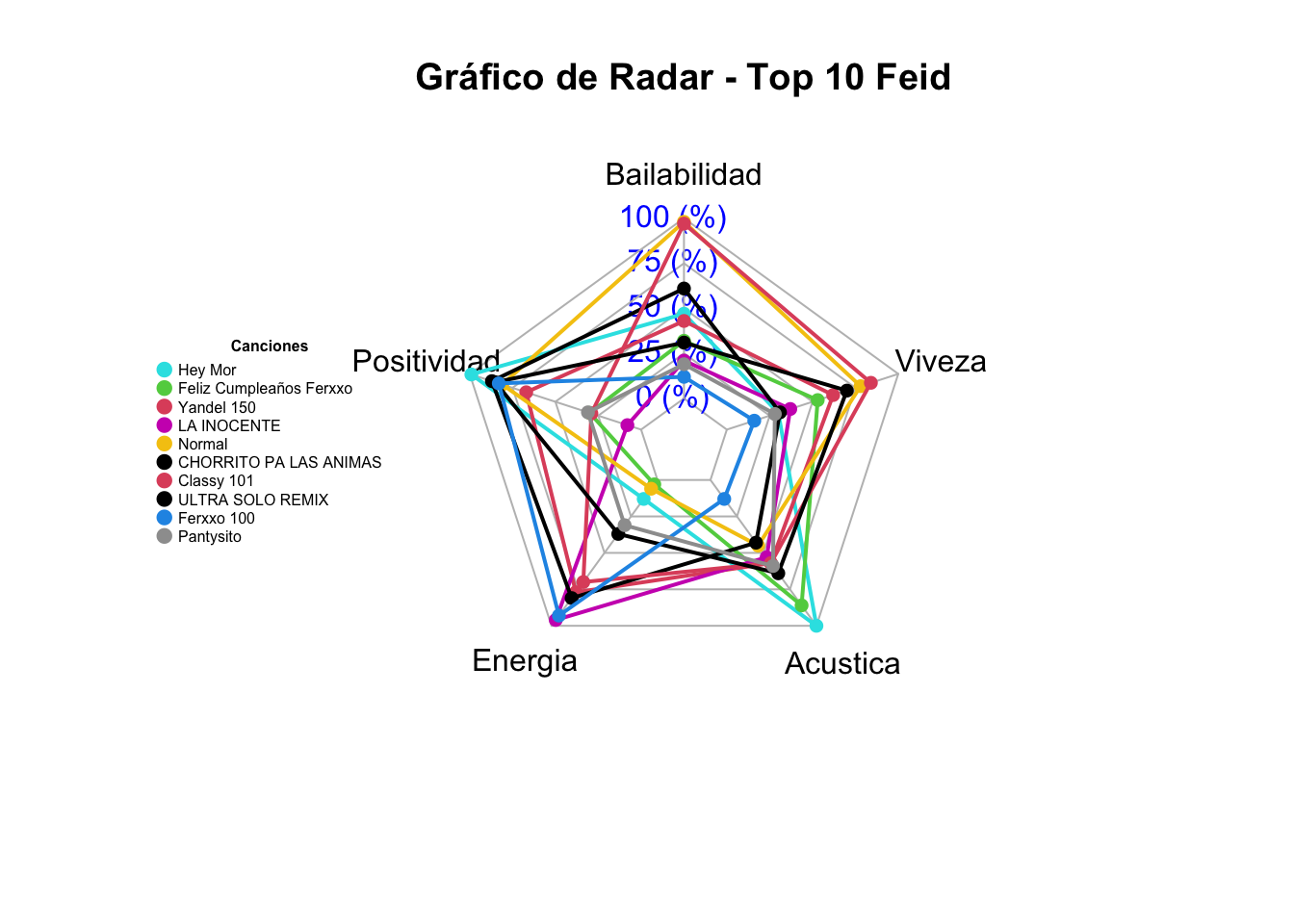
# Seleccionamos variables de interéstop_10_radar <- top_10_feid %>%select(Cancion, Bailabilidad, Positividad, Energia, Acustica, Viveza)# Creamos datos para el gráfico de radar principalset.seed(99)data_for_radar <-as.data.frame(matrix(sample(0:100, 50, replace =TRUE), ncol =5))colnames(data_for_radar) <-c("Bailabilidad", "Positividad", "Energia", "Acustica", "Viveza")# Convertimos los datos a formato longdata_for_radar_long <-pivot_longer(data_for_radar, cols =starts_with("Bailabilidad"), names_to ="Variable", values_to ="Value")# Convertimos la Variable a factordata_for_radar_long$Variable <-factor(data_for_radar_long$Variable, levels =c("Bailabilidad", "Positividad", "Energia", "Acustica", "Viveza"))# Creamos datos para el gráfico de radar adicional (EL IMPORTANTE!!!)set.seed(99)data_additional <-as.data.frame(matrix(sample(0:100, 50, replace =TRUE), ncol =5))colnames(data_additional) <-c("Bailabilidad", "Positividad", "Energia", "Acustica", "Viveza")rownames(data_additional) <-paste("Cancion", 1:10)data_additional <-rbind(rep(100, 5), rep(0, 5), data_additional)data_additional_long <-pivot_longer(data_additional, cols =starts_with("Bailabilidad"), names_to ="Cancion", values_to ="Value")data_additional_long$Cancion <-factor(data_additional_long$Cancion, levels =c("Bailabilidad", "Positividad", "Energia", "Acustica", "Viveza"))# Creamos un vector de colores numéricos para la leyendalegend_colors <-as.numeric(factor(top_10_radar$Cancion))# Creamos el gráfico de radar adicionalradarchart(data_additional, axistype =1, title ="Gráfico de Radar - Top 10 Feid", lty =1, cglty =1, cglcol ="gray", cglwd =1, pcol = legend_colors, plwd =2, plty =1)# Obtenemos el número total de canciones y las dividimos para mejorar la leyenda:num_songs <-nrow(top_10_radar)songs_row1 <- top_10_radar$Cancion[1:5]songs_row2 <- top_10_radar$Cancion[6:10]legend("left",title =expression(bold("Canciones")),legend =c(songs_row1, songs_row2),bty ="n", pch =20, col = legend_colors,text.col ="black", pt.cex =1.5, ncol =1, inset =c(-0.001, -0.04),cex =0.5)
En este apartado analizamos las canciones de Ferxxo mediante un gráfico de radar que resalta sus características distintivas. Este gráfico nos permiten apreciar la bailabilidad, positividad, energía, acústica y viveza presentes en sus canciones.
Objetivo: Analizar en detalle las características musicales de las canciones más populares de Feid.
Método: Creación de un gráfico de radar para visualizar las características como bailabilidad, positividad, energía, etc, asignando a cada canción un color.
Al profundizar en las características del TOP 10 de Ferxxo mediante el uso de un gráfico de radar, podemos obtener una visión detallada de sus peculiaridades. Esto también se puede observar en la tabla, pero aquí de manera más visual.
Viaje a través de las características individuales de nuestras canciones favoritas
#A partir de top_10_radar creamos cinco gráficos de dispersión interactivos, uno para cada caracteristica# Creamos el gráfico de ggplotcombi <-ggplot(top_10_radar, aes(x = Cancion)) +geom_point(aes(y = Bailabilidad,color ="Bailabilidad", text =paste("Bailabilidad:", round(Bailabilidad, 1))), size =3, alpha =0.7) +geom_point(aes(y = Viveza, color ="Viveza", text =paste("Viveza:", round(Viveza, 2))), size =3, alpha =0.7) +geom_point(aes(y = Positividad, color ="Positividad", text =paste("Positividad:", round(Positividad, 2))), size =3, alpha =0.7) +geom_point(aes(y = Energia, color ="Energia", text =paste("Energia:", round(Energia, 2))), size =3, alpha =0.7) +geom_point(aes(y = Acustica, color ="Acustica", text =paste("Acustica:", round(Acustica, 2))), size =3, alpha =0.7) +geom_line(aes(y = Bailabilidad, group =1), color ="purple", size =1) +geom_line(aes(y = Viveza, group =1), color ="blue", size =1) +geom_line(aes(y = Positividad, group =1), color ="pink", size =1) +geom_line(aes(y = Energia, group =1), color ="green", size =1) +geom_line(aes(y = Acustica, group =1), color ="aquamarine", size =1) +geom_text(aes(y = Bailabilidad +0.02, label =round(Bailabilidad, 2)), color ="purple", size =3, hjust =0, vjust =0.5) +geom_text(aes(y = Viveza +0.02, label =round(Viveza, 2)), color ="blue", size =3, hjust =0, vjust =0.5) +geom_text(aes(y = Positividad +0.02, label =round(Positividad, 2)), color ="pink", size =3, hjust =0, vjust =0.5) +geom_text(aes(y = Energia +0.02, label =round(Energia, 2)), color ="green", size =3, hjust =0, vjust =0.5) +geom_text(aes(y = Acustica +0.02, label =round(Acustica, 2)), color ="aquamarine", size =3, hjust =0, vjust =0.5) +scale_color_manual(values =c(Bailabilidad ="purple",Viveza ="blue",Positividad ="pink",Energia ="green",Acustica ="aquamarine" ),name ="Característica" ) +labs(title ="Gráfico de Dispersión - Todas las Características",x ="Canción",y ="Valor de la Característica",color ="Característica") +theme_minimal()# Para hacerlo interactivo:combi_plotly <-ggplotly(combi)combi_plotly
Exploramos de otra forma las características individuales de las canciones de Feid a través de gráficos de dispersión. Cada gráfico se centra en una característica única, desde la bailabilidad hasta la viveza, proporcionando una visión detallada y personalizada de la esencia musical de Ferxxo.
Objetivo: Con la representación individual de cada canción de Feid se pretende obtener una evaluación detallada de los atributos de sus canciones.
Método: Se utiliza un gráfico de dispersión donde cada punto representa una canción.
Con esto buscamos otra manera de visualizar lo mismo, pero ahora de forma visual, detallada y personalizada.
Comparación de popularidad en Spotify y Apple Music
# Normalizamos las columnas de apariciones en listas de reproducciónnormalize <-function(x) { (x -min(x, na.rm =TRUE)) / (max(x, na.rm =TRUE) -min(x, na.rm =TRUE))}newtop <- top_10_feid %>%select(Cancion, in_spotify_playlists, in_apple_playlists) %>%mutate(in_spotify_playlists_norm =normalize(in_spotify_playlists),in_apple_playlists_norm =normalize(in_apple_playlists) ) %>%filter(!is.na(in_spotify_playlists_norm) |!is.na(in_apple_playlists_norm))# Creamos el gráfico ggplot con barras horizontalescomp_playlist <-ggplot(newtop, aes(y =factor(Cancion))) +geom_bar(aes(x = in_spotify_playlists_norm, fill ="Spotify"), stat ="identity", position ="dodge") +geom_bar(aes(x = in_apple_playlists_norm, fill ="Apple Music"), stat ="identity", position ="dodge", alpha =0.5) +labs(title ="Popularidad normalizada por canción en Spotify y Apple Music",x ="Playlists normalizadas",y ="Canción") +scale_fill_manual(values =c("Spotify"="#1DB954", "Apple Music"="#FF2F54")) +theme_minimal() +theme(axis.text.y =element_text(angle =0, hjust =1)) # Para hacerlo interactivo:comp_plotly <-ggplotly(comp_playlist)comp_plotly
Examinamos la popularidad de las canciones de Feid en Spotify y Apple Music a través de un gráfico interactivo. Este análisis incluye la presencia en playlists de ambas plataformas, ofreciendo una visión personalizada de cómo las canciones de Ferxxo se posicionan en el mundo de la música en la era digital. Al contrario que en la primera parte del trabajo, se prescinde de Deezer para ver de forma más fácil la comparación.
Objetivo: Comparar la popularidad de las canciones de Feid en Spotify y Apple Music.
Método: Uso de gráficos de barras para visualizar la presencia en playlists de ambas plataformas.
La comparación de la popularidad en Spotify y Apple Music proporciona una visión valiosa de cómo las canciones de Ferxxo se posicionan en el ámbito digital. Al normalizar los datos, dado que cada plataforma difiere significativamente en el número de oyentes y la cantidad de playlists, podemos observar, por ejemplo, que “Yandel 150” destacó más en Spotify, mientras que “Normal” lo hizo en Apple Music.
Descubriendo colaboradores musicales en las canciones de Feid
# Creamos un nuevo df de artistas colaboradores y eliminamos a Feid de estos:df_colab <- df_feid %>%select(artist.s._name) %>%mutate(artist.s._name =gsub("Feid", "", artist.s._name)) %>%filter(!is.na(artist.s._name)) %>%separate_rows(artist.s._name, sep =",")%>%filter(artist.s._name !="")%>%distinct() %>%filter(artist.s._name !="")%>%mutate(artist.s._name =str_trim(artist.s._name)) %>%filter(artist.s._name !="")%>%rename("Colaboradores"= artist.s._name)set.seed(42)# Creamos el word cloud de los colaboradores:ggplot(df_colab, aes(label = Colaboradores, color = Colaboradores, size =runif(nrow(df_colab)))) +geom_text_wordcloud_area() +scale_size_area(max_size =30) +theme_minimal()
En esta sección, nos sumergimos en la exploración visual de los colaboradores que han dejado su huella en las canciones de Ferxxo. A través de un intrigante Word Cloud, cada palabra representa a un artista colaborador, y en diferentes colores. Esta representación gráfica nos brinda una visión única y artística de las conexiones que Ferxxo ha cultivado en su viaje musical.
Objetivo: Investigar las colaboraciones musicales en las canciones de Feid.
Método: Creación de un Word Cloud para representar visualmente a los artistas colaboradores.
Con la visualización a través del Word Cloud, se puede apreciar que Feid ha colaborado con artistas como Young Miko, Ozuna, Yandel, entre otros.
Conclusión: De tendencias universales a las notas únicas de Feid
En la era digital, la música encuentra su voz en nuevas frecuencias. En este trabajo hemos explorado, en primer lugar, la distribución global de reproducciones, las dinámicas estacionales, la influencia del éxito en las colaboraciones y, sobre todo, qué pueden decirnos características asignadas por Spotify a las canciones, tanto en su propio éxito medido en reproducciones, como su clasificación por similitud a través de clusters.
Posteriormente nos hemos sumergido en el universo sonoro distintivo de Ferxxo, desde sus éxitos envolventes hasta las colaboraciones tejidas en su trayectoria. Su arte, distintivo y cautivador, añade una vibración única a la melodía global, destacando la capacidad de la música para ser universal y personal al mismo tiempo. Y como en nuestros datos no lo tenemos porque es muy reciente, compartimos por aquí una de las canciones que más esta sonando últimamente: